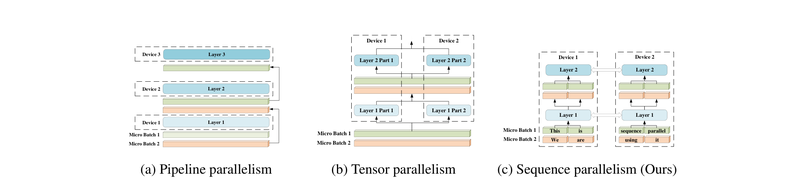
-
Tensor Parallel 구현 비교
Megatron-LM, nanotron, DeepSpeed, torchtitan, vLLM, SGLang의 Tensor Parallelism 구현을 코드 레벨에서 비교 분석합니다.

-
Flash Attention 3
Warp 특화, WGMMA 파이프라이닝, FP8 지원으로 H100 GPU에서 1.5-2배 속도 향상을 달성하는 FlashAttention-3.
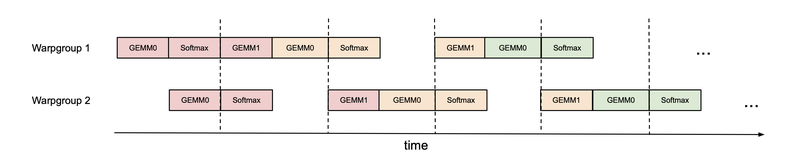
-
Flash Attention 2
작업 분배 개선, 비행렬곱 FLOPs 감소, 병렬화 향상을 통해 학습 속도를 2배로 높이는 FlashAttention-2.
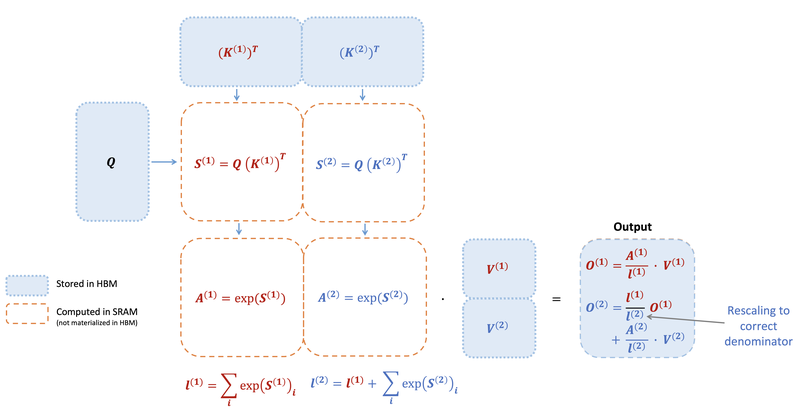
-
Flash Attention
타일링과 온라인 소프트맥스를 활용한 IO 인식 어텐션 알고리즘으로 2-3배 속도 향상과 10-20배 메모리 절감을 달성하는 FlashAttention.
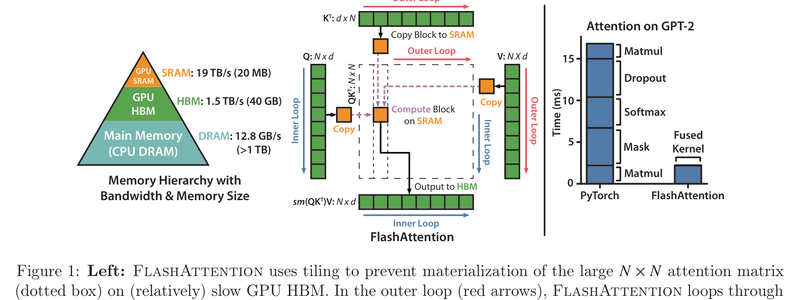
-
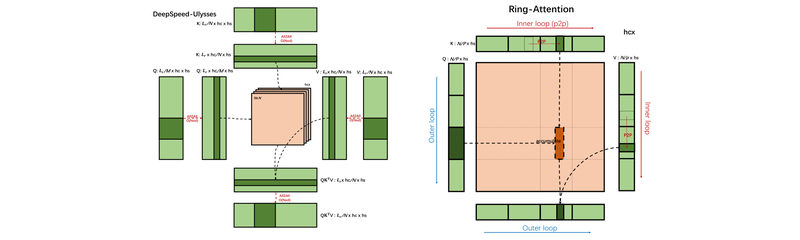
Unified Sequence Parallelism
Ulysses와 Ring Attention을 결합한 Unified Sequence Parallelism으로 208K 토큰까지의 확장 가능한 장문 시퀀스 학습.
-
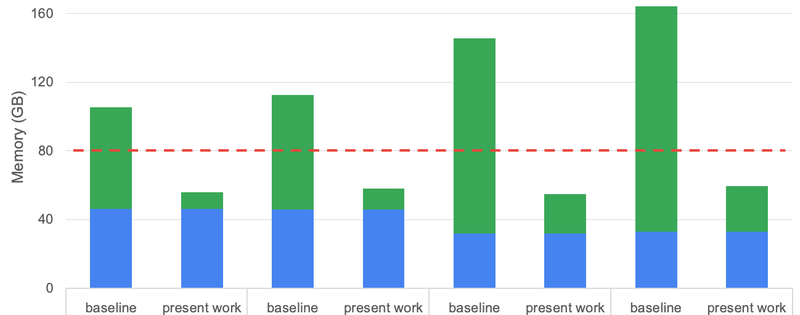
Reducing Activation Recomputation in Large Transformer Models
Sequence parallelism과 selective activation recomputation을 통한 대규모 transformer 모델의 활성화 메모리 5배 절감과 학습 처리량 30% 향상.
-
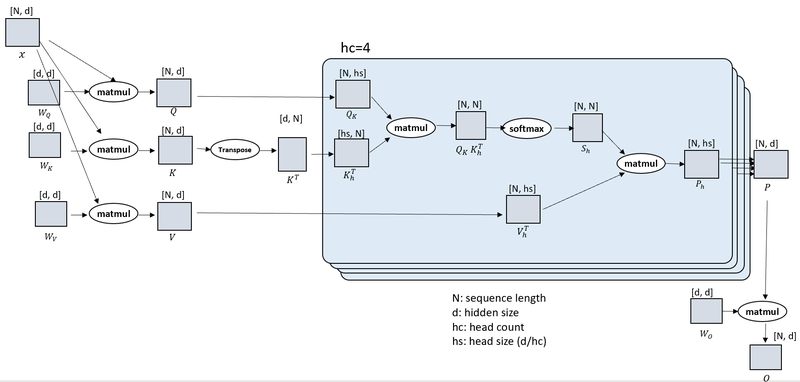
DeepSpeed Ulysses
All-to-all 통신을 통한 효율적 시퀀스 병렬화로 100만 토큰 이상의 학습을 가능케 하는 DeepSpeed-Ulysses.
-
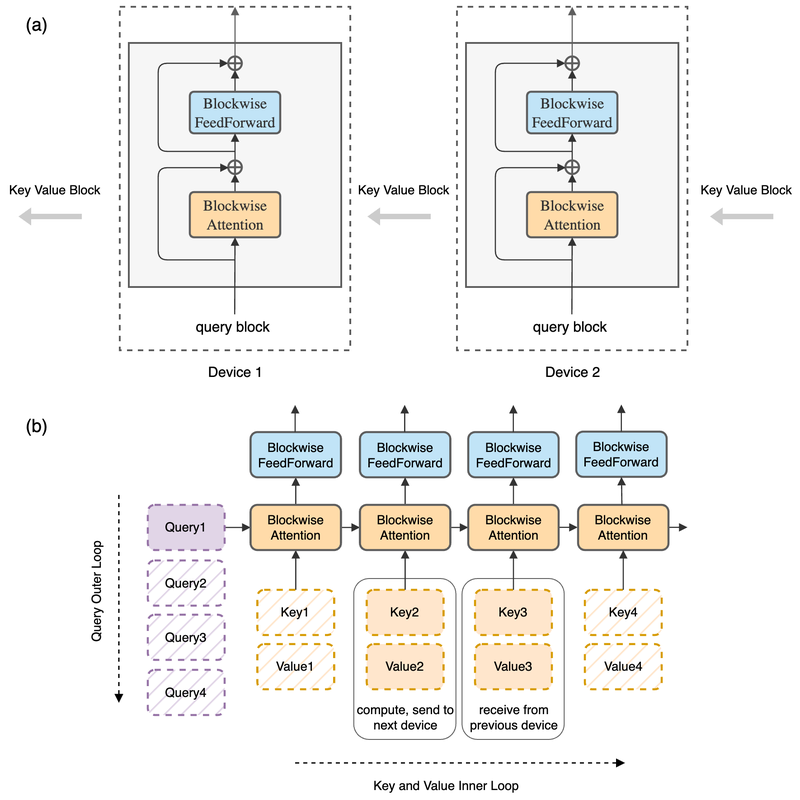
Blockwise RingAttention
Blockwise RingAttention은 blockwise attention의 순열 불변성을 활용하여 KV 블록 통신과 계산을 완전히 중첩시킴으로써, 장치 수에 선형 비례하는 컨텍스트 길이 확장을 제로 오버헤드로 달성하는 분산 시퀀스 병렬화 방법.
-
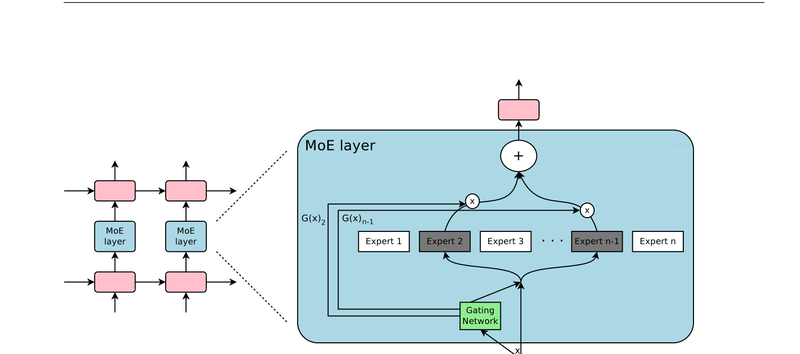
Mixture of Experts
Sparsely-Gated Mixture-of-Experts를 통한 최소 연산 오버헤드로 1000배 파라미터 확장.
-
Ring Self-Attention
Ring 통신 패턴을 활용한 GPU 간 시퀀스 병렬화로 분산 어텐션을 수행하는 Ring Self-Attention.